
In der heutigen datengetriebenen Welt ist der Zugriff auf und die effiziente Verarbeitung von großen Datenmengen entscheidend. In diesem Blogbeitrag erfahren Sie, wie wir bei IT-WINGS Google Analytics 4 (GA4) Daten mit Python Pandas aufbereiten und wichtige Key Performance Indicators (KPIs) mit Pandasql berechnen. Außerdem begründen wir die Nutzung von Pandasql und zeigen die Berechnung der Conversion Rate als Beispiel eines KPI.
1. Datenbeschaffung aus BigQuery
BigQuery ist eine leistungsstarke Plattform zur Verarbeitung von Big Data. Alle Rohdaten aus GA4, die als Grundlage für unsere Analysen dienen, erhalten wir über den Export aus BigQuery. Um mit den Rohdaten in Python weiterzuarbeiten, werden die Daten nach dem Export über eine API abgefragt. Mehr Informationen zu dem Verfahren erhalten Sie in unserem Blogartikel Einführung in Google BigQuery.
2. Datenbereinigung und Preprocessing mit Pandas
Die Daten, die wir erhalten, sind roh und unstrukturiert. Für die Bereinigung und Aufbereitung der Daten nutzen wir Pandas. Die Pandas-Funktionen können zum Beispiel für Folgendes genutzt werden:
- Entfernung von unnötigen Daten
- Ergänzung wichtiger Daten
- Verbindung wichtiger Daten
Diese Vorbereitungen sind für spätere Analysen entscheidend.
Beispiel der Verwendung einer Pandas-Funktion, zum Konkatenieren zweier DataFrames:
for df_name, df_data in dict_df.items():
df_geo = pd.concat([df_geo, df_data[geo_data]], ignore_index=True)Hier finden Sie eine Auflistung aller Funktionen von Pandas.
3. Daten aufspalten für die Performance-Optimierung
Um eine effiziente Verarbeitung der Daten zu ermöglichen, ist das separate Aufteilen der Daten in Pandas DataFrames wichtig. Dadurch werden die Daten für spezifische Analysen und Abfragen leichter zugänglich und die Verarbeitungsgeschwindigkeit erhöht.
Beispiel für die Erstellung eines separaten DataFrame für Geo Daten:
# generate dataframe for geo data
geo_data = ['unique_eventID', 'geo_continent', 'geo_country', 'geo_region', 'geo_city', 'geo_sub_continent', 'geo_metro']
df_geo = pd.DataFrame(columns=geo_data)
for df_name, df_data in dict_df.items():
df_geo = pd.concat([df_geo, df_data[geo_data]], ignore_index=True)4. Speichern der daten in Datenbanken
Die geteilten Tabellen werden in einer Datenbank gespeichert, damit die vorverarbeiteten Daten für künftige Analysen und Abfragen zugänglich bleiben. Dies ermöglicht auch eine einfachere Integration mit anderen Datenquellen und Systemen.
Beispiel für das Speichern der Geo Daten in einer Datenbank:
# loading data into the database
table_name = 'silver_ga_geo'
df_geo.to_sql(name=table_name, con=engine, if_exists ='append', index= False)5. Verwendung von Pandasql für KPI-Berechnungen
Ein wichtiger Schritt im Prozess ist die Berechnung von KPIs: Wir verwenden Pandasql, um verschiedene KPIs aus unseren vorverarbeiteten Daten abzurufen. Aber warum Pandasql?
Pandasql bietet eine nahtlose Integration von SQL-Abfragen in die Pandas-Bibliothek. Dadurch können wir die leistungsstarke SQL-Syntax nutzen, um komplexe Abfragen auf unseren Daten durchzuführen, und gleichzeitig von den Datenverarbeitungsfunktionen von Pandas profitieren. Diese Kombination macht Pandasql zur idealen Wahl für unsere KPI-Berechnungen.
Hier finden Sie Infos zu Pandasql.
6. Berechnung der Conversion Rate
Ein Beispiel für eine KPI, die wir mit Pandasql berechnen, ist die „Conversion Rate“. Diese wurden wie folgt berechnet:
- Wir importieren die erforderlichen Bibliotheken.
- Wir stellen eine Verbindung zu der Datenbank her, in der unsere Rohdaten gespeichert sind. Hierfür verwenden wir SQLAlchemy, ein Python-SQL-Toolkit, als Beispiel.
- Wir fragen unsere benötigten Daten über die Datenbankverbindung ab und speichern sie in einem Pandas DataFrame.
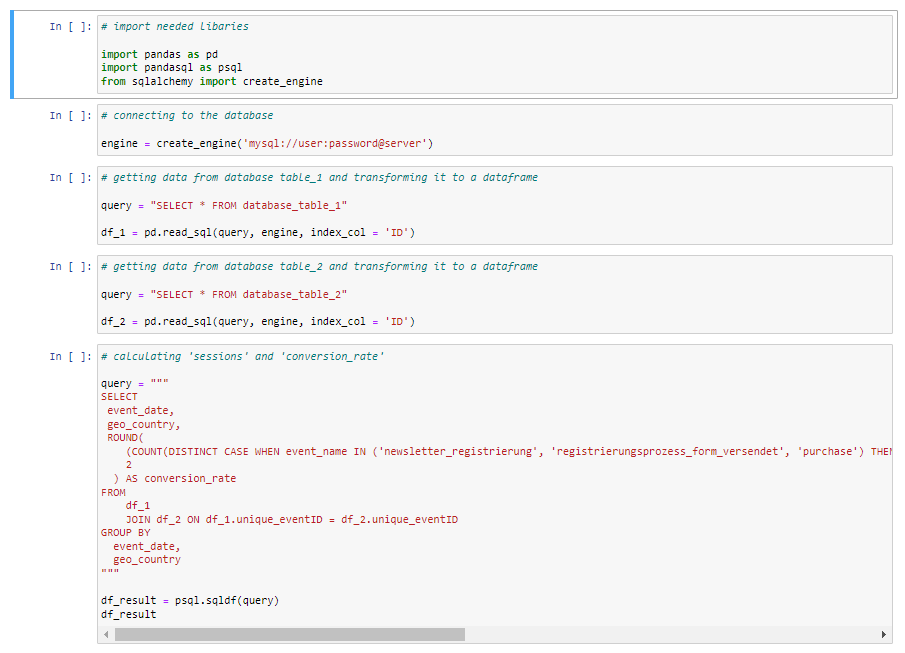
- Nun schreiben wir unsere Abfrage, um die gewünschte Kennzahl zu berechnen. Dazu kombinieren wir die Daten aus unseren Tabellen mit einer JOIN-Klausel. Als Basis verwenden wir eine eindeutige Ereignis-ID, die wir jedem Dateneintrag während der Vorverarbeitung zugewiesen haben. Neben der KPI wählen wir auch das Datum und das Land aus, da wir diese als Dimensionen sehen wollen. Zur Berechnung der Conversion Rate zählen wir eindeutige Ereignisse, bei denen die von uns definierten Conversion Events auftreten. In diesem Fall ist es ein „Kauf“, eine „Registrierung“ oder eine „Newsletter-Anmeldung“. Wir teilen dies durch die Anzahl unserer Sitzungen, um die gewünschte Conversion Rate zu erhalten. Wir gruppieren nach unserer Dimension, um die gewünschte Visualisierung zu erhalten.
- Wir erstellen aus dem Ergebnis ein DataFrame, was uns die weitere Analyse und Visualisierung der Ergebnisse sowie die Integration in unsere Berichterstattung und Dashboards ermöglicht.
Vereinfachtes Beispiel zu Berechnung der Conversion Rate:
In diesem Blogbeitrag haben wir Ihnen gezeigt, wie wir bei IT-WINGS wichtige GA4 KPIs mit Hilfe Pandasql berechnen. Dieser Prozess ermöglicht es uns, wertvolle Erkenntnisse aus unseren Daten zu gewinnen und fundierte Geschäftsentscheidungen zu treffen.
Pandas und Pandasql sind leistungsstarke Werkzeuge für Datenanalysten und Datenwissenschaftler, die mit großen Datensätzen arbeiten. Sie helfen uns, Daten effizient zu verarbeiten und wertvolle Erkenntnisse zu gewinnen.
Wir hoffen, dass Ihnen dieser Einblick in unseren Datenverarbeitungsprozess nützlich war. Sollten Sie Fragen zum Datenverarbeitungsprozess haben, freuen wir uns von Ihnen zu hören. Wir unterstützen Sie gerne bei Ihrer Datenanalyse oder der Verarbeitung wichtiger Daten. Bleiben Sie dran für weitere spannende Beiträge zur Datenanalyse und -verarbeitung bei IT-WINGS!